-
1. Começando
- 1.1 Sobre Controle de Versão
- 1.2 Uma Breve História do Git
- 1.3 O Básico do Git
- 1.4 A Linha de Comando
- 1.5 Instalando o Git
- 1.6 Configuração Inicial do Git
- 1.7 Pedindo Ajuda
- 1.8 Sumário
-
2. Fundamentos de Git
-
3. Branches no Git
-
4. Git on the Server
- 4.1 The Protocols
- 4.2 Getting Git on a Server
- 4.3 Generating Your SSH Public Key
- 4.4 Setting Up the Server
- 4.5 Git Daemon
- 4.6 Smart HTTP
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 Third Party Hosted Options
- 4.10 Summary
-
5. Distributed Git
-
6. GitHub
- 6.1 Configurando uma conta
- 6.2 Contribuindo em um projeto
- 6.3 Maintaining a Project
- 6.4 Managing an organization
- 6.5 Scripting GitHub
- 6.6 Summary
-
7. Git Tools
- 7.1 Revision Selection
- 7.2 Interactive Staging
- 7.3 Stashing and Cleaning
- 7.4 Signing Your Work
- 7.5 Searching
- 7.6 Rewriting History
- 7.7 Reset Demystified
- 7.8 Advanced Merging
- 7.9 Rerere
- 7.10 Debugging with Git
- 7.11 Submodules
- 7.12 Bundling
- 7.13 Replace
- 7.14 Credential Storage
- 7.15 Summary
-
8. Customizing Git
- 8.1 Git Configuration
- 8.2 Git Attributes
- 8.3 Git Hooks
- 8.4 An Example Git-Enforced Policy
- 8.5 Summary
-
9. Git and Other Systems
- 9.1 Git as a Client
- 9.2 Migrating to Git
- 9.3 Summary
-
10. Funcionamento Interno do Git
- 10.1 Encanamento e Porcelana
- 10.2 Objetos do Git
- 10.3 Referências do Git
- 10.4 Packfiles
- 10.5 The Refspec
- 10.6 Transfer Protocols
- 10.7 Maintenance and Data Recovery
- 10.8 Variáveis de ambiente
- 10.9 Sumário
-
A1. Appendix A: Git em Outros Ambientes
- A1.1 Graphical Interfaces
- A1.2 Git in Visual Studio
- A1.3 Git in Eclipse
- A1.4 Git in Bash
- A1.5 Git in Zsh
- A1.6 Git in Powershell
- A1.7 Resumo
-
A2. Appendix B: Embedding Git in your Applications
- A2.1 Command-line Git
- A2.2 Libgit2
- A2.3 JGit
-
A3. Appendix C: Git Commands
- A3.1 Setup and Config
- A3.2 Getting and Creating Projects
- A3.3 Basic Snapshotting
- A3.4 Branching and Merging
- A3.5 Sharing and Updating Projects
- A3.6 Inspection and Comparison
- A3.7 Debugging
- A3.8 Patching
- A3.9 Email
- A3.10 External Systems
- A3.11 Administration
- A3.12 Plumbing Commands
3.6 Branches no Git - Rebase
Rebase
No Git, existem duas maneiras principais de integrar as mudanças de um branch para outro: o merge e o rebase.
Nesta seção, você aprenderá o que é o rebase, como fazê-lo, por que é uma ferramenta incrível e em que casos não vai querer usá-la.
O básico do Rebase
Se você voltar a um exemplo anterior de Mesclagem Básica, você pode ver que o seu trabalho divergiu e fez commits em dois branches diferentes.
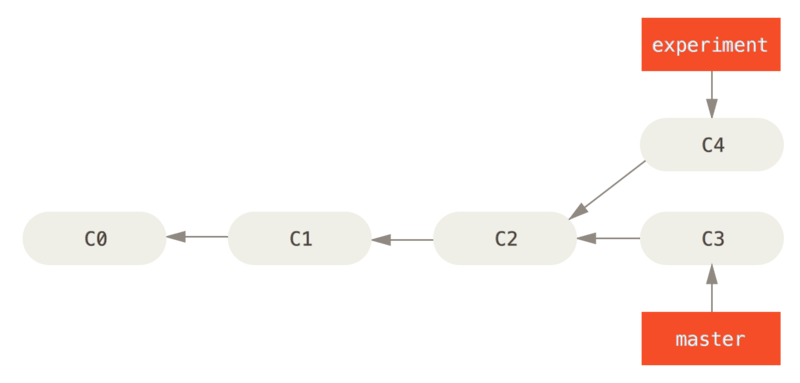
A maneira mais fácil de integrar os branches, como já vimos, é o comando merge.
Ele realiza uma fusão de três vias entre os dois últimos snapshots de branch (C3 e C4) e o ancestral comum mais recente dos dois (C2), criando um novo snapshot (e commit).
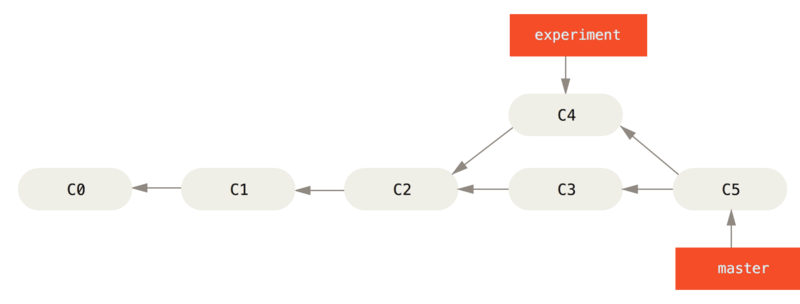
No entanto, há outra maneira: você pode pegar o patch da mudança que foi introduzida no C4 e reaplicá-lo em cima do C3.
No Git, isso é chamado de rebasing.
Com o comando rebase, você pode pegar todas as alterações que foram confirmadas em um branch e reproduzi-las em outro.
Neste exemplo, você executaria o seguinte:
$ git checkout experiment
$ git rebase master
First, rewinding head to replay your work on top of it...
Applying: added staged commandEle funciona indo para o ancestral comum dos dois branches (aquele em que você está e aquele em que você está fazendo o rebase), obtendo o diff introduzido por cada commit do branch em que você está, salvando esses diffs em arquivos temporários, redefinindo o branch atual para o mesmo commit do branch no qual você está fazendo o rebase e, finalmente, aplicando cada mudança por vez.
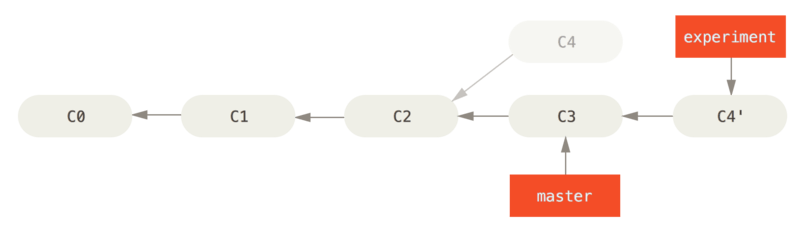
C4 em C3
Neste ponto, você pode voltar ao branch master e fazer uma fusão rápida.
$ git checkout master
$ git merge experiment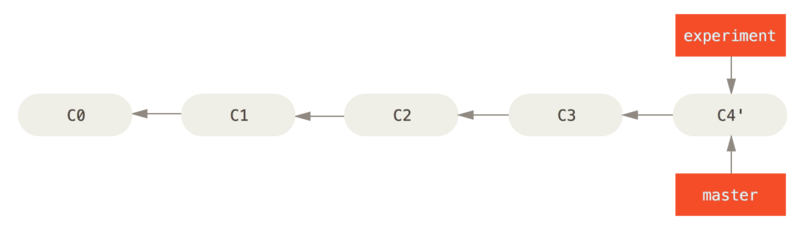
Agora, o snapshot apontado por C4' é exatamente o mesmo que foi apontado por C5 no exemplo de merge.
Não há diferença no produto final da integração, mas o rebase contribui para um histórico mais limpo.
Se você examinar o log de um branch que foi feito rebase, parece uma registro linear: parece que todo o trabalho aconteceu em série, mesmo quando originalmente aconteceu em paralelo.
Frequentemente, você fará isso para garantir que seus commits sejam aplicados de forma limpa em um branch remoto - talvez em um projeto para o qual você está tentando contribuir, mas que não mantém.
Neste caso, você faria seu trabalho em um branch e então realocaria seu trabalho em origin/master quando estivesse pronto para enviar seus patches para o projeto principal.
Dessa forma, o mantenedor não precisa fazer nenhum trabalho de integração - apenas um fusão rápida ou uma aplicação limpa.
Observe que o snapshot apontado pelo commit final com o qual você termina, seja o último dos commits para um rebase ou o commit final de mesclagem após um merge, é o mesmo snapshot - é apenas o histórico que é diferente. O Rebase reproduz as alterações de uma linha de trabalho para outra na ordem em que foram introduzidas, enquanto a mesclagem pega os finais e os mescla.
Rebases mais interessantes
Você também pode fazer o replay do rebase em algo diferente do branch de destino.
Pegue um histórico como Um histórico com um tópico de branch de outro branch, por exemplo.
Você ramificou um branch de tópico (server) para adicionar alguma funcionalidade do lado do servidor ao seu projeto e fez um commit.
Então, você ramificou isso para fazer as alterações do lado do cliente (client) e fez commit algumas vezes.
Finalmente, você voltou ao seu branch de servidor e fez mais alguns commits.
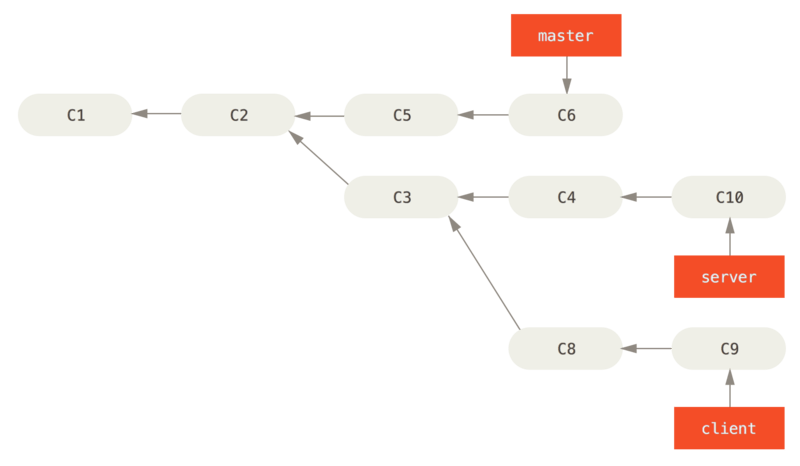
Suponha que você decida que deseja mesclar suas alterações do lado do cliente em sua linha principal para um lançamento, mas deseja adiar as alterações do lado do servidor até que seja testado mais profundamente.
Você pode pegar as mudanças no cliente que não está no servidor (C8 e C9) e reproduzi-las em seu branch master usando a opção --onto do git rebase:
$ git rebase --onto master server clientIsso basicamente diz: “Pegue o branch client, descubra os patches, desde que divergiu do branch server, e repita esses patches no branch client como se fosse baseado diretamente no branch master.”
É um pouco complexo, mas o resultado é bem legal.
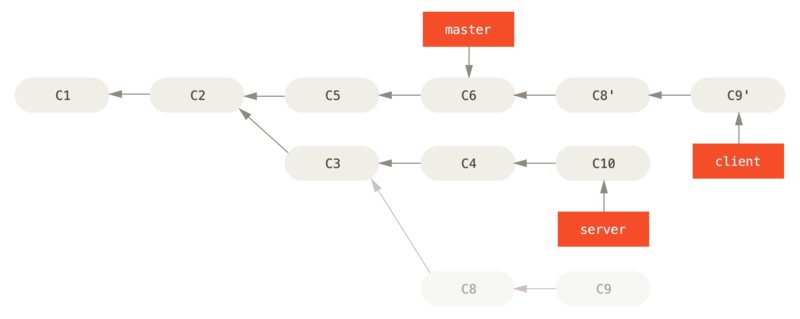
Agora, você pode fazer uma fusão rápida no branch master (veja Avanço rápido de seu branch principal para incluir as alterações da branch do cliente):
$ git checkout master
$ git merge client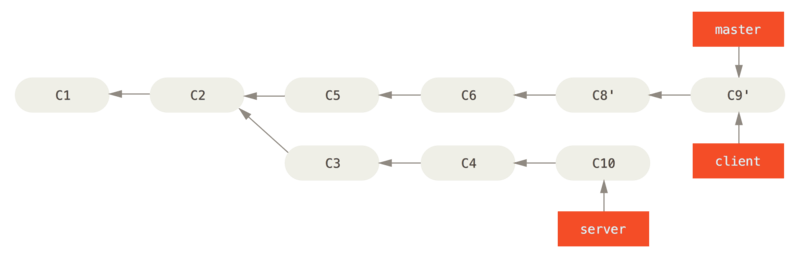
Digamos que você decida puxar seu branch de servidor também.
Você pode realocar o branch do servidor no branch master sem ter que verificá-lo primeiro executando git rebase [basebranch] [topicbranch] - que verifica o branch do tópico (neste caso, server) para você e repete no branch base (master):
$ git rebase master serverIsso reproduz o trabalho do server em cima do trabalho do master, como mostrado em Rebase o branch server por cima do branch master.

Então, você pode avançar o branch base (master):
$ git checkout master
$ git merge serverVocê pode remover os branches client e server porque todo o trabalho foi integrado e você não precisa mais deles, deixando seu histórico para todo o processo parecido com Histórico final de commits:
$ git branch -d client
$ git branch -d server
Os perigos do Rebase
Ahh, mas a felicidade do rebase não vem sem suas desvantagens, que podem ser resumidas em uma única linha:
Não faça rebase de commits que existam fora do seu repositório.
Se você seguir essa diretriz, ficará bem. Do contrário, as pessoas irão odiá-lo e você será desprezado por amigos e familiares.
Quando você faz o rebase, você está abandonando commits existentes e criando novos que são semelhantes, mas diferentes.
Se você enviar commits para algum lugar e outros puxá-los para baixo e trabalhar com base neles, e então você reescrever esses commits com git rebase e colocá-los novamente, seus colaboradores terão que fazer um novo merge em seus trabalhos e as coisas ficarão complicadas quando você tentar puxar o trabalho deles de volta para o seu.
Vejamos um exemplo de como o rebase de um trabalho que você tornou público pode causar problemas. Suponha que você clone de um servidor central e faça algum trabalho a partir dele. Seu histórico de commits é parecido com este:
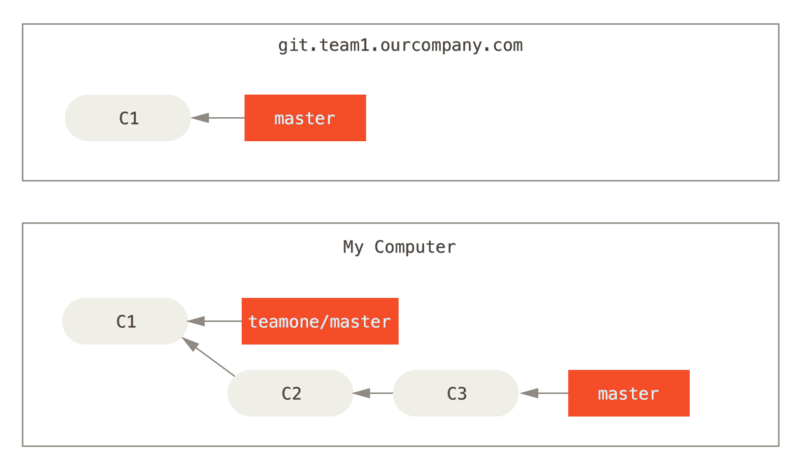
Agora, outra pessoa faz mais alterações que inclui um merge e envia esse trabalho para o servidor central. Você o busca e mescla o novo branch remoto em seu trabalho, fazendo com que seu histórico se pareça com isto:
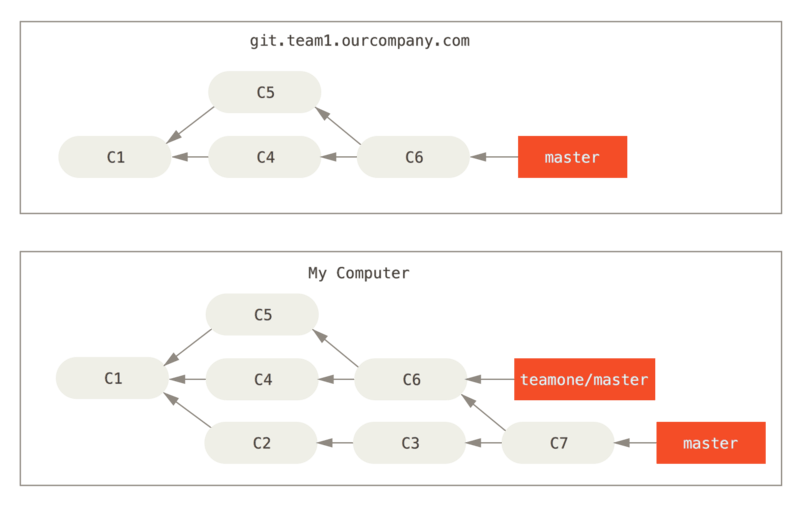
Em seguida, a pessoa que empurrou o trabalho mesclado decide voltar e realocar seu trabalho; eles fazem um git push --force para sobrescrever o histórico no servidor.
Você então busca daquele servidor, derrubando os novos commits.
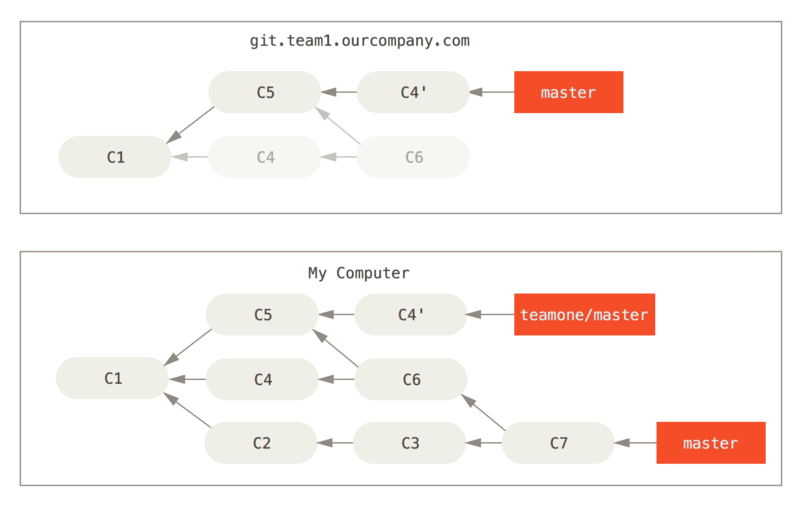
Agora você está em apuros.
Se você fizer um git pull, você criará um commit de merge que inclui as duas linhas do histórico, e seu repositório ficará assim:
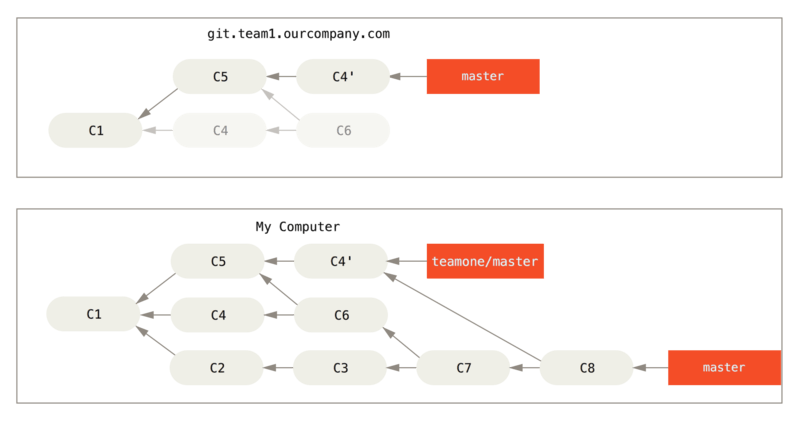
Se você executar um git log quando seu histórico estiver assim, você verá dois commits com o mesmo autor, data e mensagem, o que será confuso.
Além disso, se você enviar esse histórico de volta ao servidor, reintroduzirá todos os commits realocados no servidor central, o que pode confundir ainda mais as pessoas.
É bastante seguro assumir que o outro desenvolvedor não quer que C4 e C6 apareçam na história; é por isso que eles fizeram um rebase antes.
Rebase quando vocês faz Rebase
Se você realmente se encontrar em uma situação como essa, o Git tem mais alguma mágica que pode te ajudar. Se alguém em sua equipe forçar mudanças que substituam o trabalho no qual você se baseou, seu desafio é descobrir o que é seu e o que eles reescreveram.
Acontece que, além da soma de verificação SHA-1 de commit, o Git também calcula uma soma de verificação que é baseada apenas no patch introduzido com a confirmação. Isso é chamado de “patch-id”.
Se você puxar o trabalho que foi reescrito e fazer o rebase sobre os novos commits de seu parceiro, o Git pode muitas vezes descobrir o que é exclusivamente seu e aplicá-lo de volta ao novo branch.
Por exemplo, no cenário anterior, se em vez de fazer uma fusão quando estamos em Alguém empurra commits que foram feitos rebase, abandonando commits nos quais você baseou seu trabalho executarmos git rebase teamone/master, Git irá:
-
Determine qual trabalho é exclusivo para nosso branch (C2, C3, C4, C6, C7)
-
Determine quais não são confirmações de merge (C2, C3, C4)
-
Determine quais não foram reescritos no branch de destino (apenas C2 e C3, uma vez que C4 é o mesmo patch que C4')
-
Aplique esses commits no topo de
teamone/master
Então, em vez do resultado que vemos em Você faz o merge do mesmo trabalho novamente em um novo commit de merge, acabaríamos com algo mais parecido com Rebase on top of force-pushed rebase work..
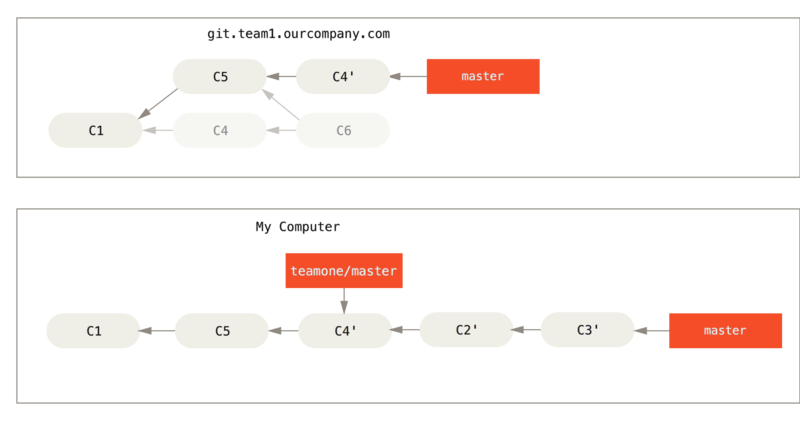
Isso só funciona se C4 e C4' que seu parceiro fez forem quase exatamente o mesmo patch. Caso contrário, o rebase não será capaz de dizer o que é uma duplicata e adicionará outro patch semelhante ao C4 (que provavelmente não será aplicado, uma vez que as alterações já estariam pelo menos um pouco lá).
Você também pode simplificar isso executando um git pull --rebase em vez de um git pull normal.
Ou você poderia fazer isso manualmente com um git fetch seguido por um git rebase teamone/master neste caso.
Se você estiver usando git pull e quiser tornar --rebase o padrão, você pode definir o valor de configuração pull.rebase com algo como git config --global pull.rebase true.
Se você tratar o rebase como uma forma de limpar e trabalhar com commits antes de enviá-los, e se você apenas fazer o rebase dos commits que nunca estiveram disponíveis publicamente, então você ficará bem. Se você fizer o rebase dos commits que já foram enviados publicamente, e as pessoas podem ter baseado o trabalho nesses commits, então você pode ter alguns problemas frustrantes e o desprezo de seus companheiros de equipe.
Se você ou um parceiro achar necessário em algum ponto, certifique-se de que todos saibam executar git pull --rebase para tentar tornar a dor depois que ela acontecer um pouco mais simples.
Rebase vs. Merge
Agora que você viu o rebase e o merge em ação, pode estar se perguntando qual é o melhor. Antes de respondermos, vamos voltar um pouco e falar sobre o que a história significa.
Um ponto de vista sobre isso é que o histórico de commit do seu repositório é um registro do que realmente aconteceu. É um documento histórico, valioso por si só, e não deve ser alterado. Desse ângulo, mudar o histórico de commits é quase uma blasfêmia; você está mentindo sobre o que realmente aconteceu. E daí se houvesse uma série confusa de commits de merge? Foi assim que aconteceu, e o repositório deve preservar isso para a posteridade.
O ponto de vista oposto é que o histórico de commits é a história de como seu projeto foi feito. Você não publicaria o primeiro rascunho de um livro, e o manual de como manter seu software merece uma edição cuidadosa. Este é o campo que usa ferramentas como rebase e filter-branch para contar a história da maneira que for melhor para futuros leitores.
Agora, à questão de saber se merge ou rebase é melhor: espero que você veja que não é tão simples. O Git é uma ferramenta poderosa e permite que você faça muitas coisas para e com sua história, mas cada equipe e cada projeto são diferentes. Agora que você sabe como essas duas coisas funcionam, cabe a você decidir qual é a melhor para sua situação específica.
Em geral, a maneira de obter o melhor dos dois mundos é fazer o rebase nas mudanças locais que você fez, mas não compartilhou ainda antes de empurrá-las para limpar seu histórico, mas nunca faça rebase em algo que você empurrou em algum lugar.