-
1. Começando
- 1.1 Sobre Controle de Versão
- 1.2 Uma Breve História do Git
- 1.3 O Básico do Git
- 1.4 A Linha de Comando
- 1.5 Instalando o Git
- 1.6 Configuração Inicial do Git
- 1.7 Pedindo Ajuda
- 1.8 Sumário
-
2. Fundamentos de Git
-
3. Branches no Git
-
4. Git on the Server
- 4.1 The Protocols
- 4.2 Getting Git on a Server
- 4.3 Generating Your SSH Public Key
- 4.4 Setting Up the Server
- 4.5 Git Daemon
- 4.6 Smart HTTP
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 Third Party Hosted Options
- 4.10 Summary
-
5. Distributed Git
-
6. GitHub
- 6.1 Configurando uma conta
- 6.2 Contribuindo em um projeto
- 6.3 Maintaining a Project
- 6.4 Managing an organization
- 6.5 Scripting GitHub
- 6.6 Summary
-
7. Git Tools
- 7.1 Revision Selection
- 7.2 Interactive Staging
- 7.3 Stashing and Cleaning
- 7.4 Signing Your Work
- 7.5 Searching
- 7.6 Rewriting History
- 7.7 Reset Demystified
- 7.8 Advanced Merging
- 7.9 Rerere
- 7.10 Debugging with Git
- 7.11 Submodules
- 7.12 Bundling
- 7.13 Replace
- 7.14 Credential Storage
- 7.15 Summary
-
8. Customizing Git
- 8.1 Git Configuration
- 8.2 Git Attributes
- 8.3 Git Hooks
- 8.4 An Example Git-Enforced Policy
- 8.5 Summary
-
9. Git and Other Systems
- 9.1 Git as a Client
- 9.2 Migrating to Git
- 9.3 Summary
-
10. Funcionamento Interno do Git
- 10.1 Encanamento e Porcelana
- 10.2 Objetos do Git
- 10.3 Referências do Git
- 10.4 Packfiles
- 10.5 The Refspec
- 10.6 Transfer Protocols
- 10.7 Maintenance and Data Recovery
- 10.8 Variáveis de ambiente
- 10.9 Sumário
-
A1. Appendix A: Git em Outros Ambientes
- A1.1 Graphical Interfaces
- A1.2 Git in Visual Studio
- A1.3 Git in Eclipse
- A1.4 Git in Bash
- A1.5 Git in Zsh
- A1.6 Git in Powershell
- A1.7 Resumo
-
A2. Appendix B: Embedding Git in your Applications
- A2.1 Command-line Git
- A2.2 Libgit2
- A2.3 JGit
-
A3. Appendix C: Git Commands
- A3.1 Setup and Config
- A3.2 Getting and Creating Projects
- A3.3 Basic Snapshotting
- A3.4 Branching and Merging
- A3.5 Sharing and Updating Projects
- A3.6 Inspection and Comparison
- A3.7 Debugging
- A3.8 Patching
- A3.9 Email
- A3.10 External Systems
- A3.11 Administration
- A3.12 Plumbing Commands
2.2 Fundamentos de Git - Gravando Alterações em Seu Repositório
Gravando Alterações em Seu Repositório
Você tem um verdadeiro repositório Git e um "checkout" ou cópia de trabalho dos arquivos para aquele projeto. Você precisa fazer algumas alterações e adicionar commits dessas alterações em seu repositório a cada vez que o projeto chegar a um estado que você queira registrar.
Lembre-se que cada arquivo em seu diretório de trabalho pode estar em um dos seguintes estados: rastreado e não-rastreado. Arquivos rastreados são arquivos que foram incluídos no último snapshot; eles podem ser não modificados, modificados ou preparados (adicionados ao stage). Em resumo, arquivos rastreados são os arquivos que o Git conhece.
Arquivos não rastreados são todos os outros - quaisquer arquivos em seu diretório de trabalho que não foram incluídos em seu último snapshot e não estão na área de stage. Quando você clona um repositório pela primeira vez, todos os seus arquivos serão rastreados e não modificados já que o Git acabou de obtê-los e você ainda não editou nada.
Assim que você edita alguns arquivos, Git os considera modificados, porque você os editou desde o seu último commit. Você prepara os arquivos editados e então faz commit das suas alterações, e o ciclo se repete.
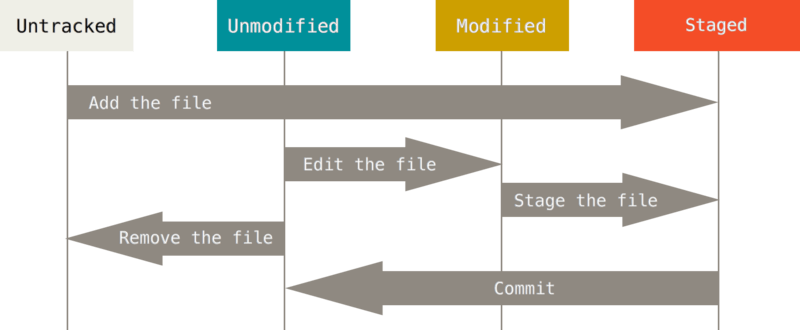
Verificando os Status de Seus Arquivos
A principal ferramenta que você vai usar para determinar quais arquivos estão em qual estado é o comando git status.
Se você executar esse comando imediatamente após clonar um repositório, você vai ver algo assim:
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
nothing to commit, working directory cleanIsso significa que você tem um diretório de trabalho limpo - em outras palavras, nenhum de seus arquivos rastreados foi modificado. O Git também não está vendo nenhum arquivo não rastreado, senão eles estariam listados aqui. Finalmente, o comando lhe diz qual o branch que você está e diz que ele não divergiu do mesmo branch no servidor. Por enquanto, esse branch é sempre “master”, que é o padrão; você não precisa se preocupar com isso agora. [ch03-git-branching] vai abordar branches e referências em detalhe.
Digamos que você adiciona um novo arquivo no seu projeto, um simples arquivo README.
Se o arquivo não existia antes, e você executar git status, você verá seu arquivo não rastreado da seguinte forma:
$ echo 'My Project' > README
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Untracked files:
(use "git add <file>..." to include in what will be committed)
README
nothing added to commit but untracked files present (use "git add" to track)Você pode ver que o seu novo arquivo README é um arquivo não rastreado, porque está abaixo do subtítulo “Untracked files” na saída do seu status. "Não rastreado" basicamente significa que o Git vê um arquivo que você não tinha no snapshot (commit) anterior; o Git não vai passar a incluir o arquivo nos seus commits a não ser que você o mande fazer isso explicitamente. O comportamento do Git é dessa forma para que você não inclua acidentalmente arquivos binários gerados automaticamente ou outros arquivos que você não deseja incluir. Você quer incluir o arquivo README, então vamos comeaçar a rastreá-lo.
Rastreando Arquivos Novos
Para começar a rastrear um novo arquivo, você deve usar o comando git add.
Para começar a rastrear o arquivo README, você deve executar o seguinte:
$ git add READMEExecutando o comando status novamente, você pode ver que seu README agora está sendo rastreado e preparado (staged) para o commit:
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: READMEÉ possível saber que o arquivo está preparado porque ele aparece sob o título “Changes to be committed”.
Se você fizer um commit neste momento, a versão do arquivo que existia no instante em que você executou git add, é a que será armazenada no histórico de snapshots.
Você deve se lembrar que, quando executou git init anteriormente, em seguida, você também executou git add (arquivos) - isso foi para começar a rastrear os arquivos em seu diretório.
O comando git add recebe o caminho de um arquivo ou de um diretório. Se for um diretório, o comando adiciona todos os arquivos contidos nesse diretório recursivamente.
Preparando Arquivos Modificados
Vamos modificar um arquivo que já estava sendo rastreado.
Se você modificar o arquivo CONTRIBUTING.md, que já era rastreado, e então executar git status novamente, você deve ver algo como:
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: README
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: CONTRIBUTING.mdO arquivo CONTRIBUTING.md aparece sob a seção “Changes not staged for commit” — que indica que um arquivo rastreado foi modificado no diretório de trabalho mas ainda não foi mandado para o stage (preparado).
Para mandá-lo para o stage, você precisa executar o comando git add.
O git add é um comando de múltiplos propósitos: serve para começar a rastrear arquivos e também para outras coisas, como marcar arquivos que estão em conflito de mesclagem como resolvidos.
Pode ser útil pensar nesse comando mais como “adicione este conteúdo ao próximo commit”.
Vamos executar git add agora, para mandar o arquivo CONTRIBUTING.md para o stage, e então executar git status novamente:
$ git add CONTRIBUTING.md
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: README
modified: CONTRIBUTING.mdAmbos os arquivos estão preparados (no stage) e entrarão no seu próximo commit.
Neste momento, suponha que você se lembre de uma pequena mudança que quer fazer no arquivo CONTRIBUTING.md antes de fazer o commit.
Você abre o arquivo, faz a mudança e está pronto para fazer o commit.
No entanto, vamos executar git status mais uma vez:
$ vim CONTRIBUTING.md
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: README
modified: CONTRIBUTING.md
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: CONTRIBUTING.mdQue negócio é esse?
Agora o CONTRIBUTING.md está listado como preparado (staged) e também como não-preparado (unstaged).
Como isso é possível?
Acontece que o Git põe um arquivo no stage exatamente como ele está no momento em que você executa o comando git add.
Se você executar git commit agora, a versão do CONTRIBUTING.md que vai para o repositório é aquela de quando você executou git add, não a versão que está no seu diretório de trabalho.
Se você modificar um arquivo depois de executar git add, você tem que executar git add de novo para por sua versão mais recente no stage:
$ git add CONTRIBUTING.md
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: README
modified: CONTRIBUTING.mdStatus Curto
Ao mesmo tempo que a saída do git status é bem completa, ela também é bastante verbosa.
O Git também tem uma flag para status curto, que permite que você veja suas alterações de forma mais compacta.
Se você executar git status -s ou git status --short a saída do comando vai ser bem mais simples:
$ git status -s
M README
MM Rakefile
A lib/git.rb
M lib/simplegit.rb
?? LICENSE.txtArquivos novos que não são rastreados têm um ?? do lado, novos arquivos que foram adicionados à área de stage têm um A, arquivos modificados têm um M e assim por diante.
Há duas colunas de status na saída: a coluna da esquerda indica o status da área de stage e a coluna da direita indica o status do diretório de trabalho.
No exemplo anterior, o arquivo README foi modificado no diretório de trabalho mas ainda não foi para o stage, enquanto o arquivo lib/simplegit.rb foi modificado e foi para o stage.
O arquivo Rakefile foi modificado, foi para o stage e foi modificado de novo, de maneira que há alterações para ele tanto no estado preparado quanto no estado não-preparado.
Ignorando Arquivos
Frequentemente você terá uma classe de arquivos que não quer que sejam adicionados automaticamente pelo Git e nem mesmo que ele os mostre como não-rastreados.
Geralmente, esses arquivos são gerados automaticamente, tais como arquivos de log ou arquivos produzidos pelo seu sistema de compilação (build).
Nesses casos, você pode criar um arquivo chamado .gitignore, contendo uma lista de padrões de nomes de arquivo que devem ser ignorados.
Aqui está um exemplo de arquivo .gitignore:
$ cat .gitignore
*.[oa]
*~A primeira linha diz ao Git para ignorar todos os arquivos que terminem com “.o” ou “.a” – arquivos objeto ou de arquivamento, que podem ser produtos do processo de compilação.
A segunda linha diz ao Git para ignorar todos os arquivos cujo nome termine com um til (~), que é usado por muitos editores de texto, como o Emacs, para marcar arquivos temporários.
Você também pode incluir diretórios log, tmp ou pid; documentação gerada automaticamente; e assim por diante.
Configurar um arquivo .gitignore, antes de você começar um repositório, geralmente é uma boa ideia para que você não inclua acidentalmente em seu repositório Git arquivos que você não quer.
As regras para os padrões que podem ser usados no arquivo .gitignore são as seguintes:
-
Linhas em branco ou começando com
#são ignoradas. -
Os padrões que normalmente são usados para nomes de arquivos funcionam.
-
Você pode iniciar padrões com uma barra (
/) para evitar recursividade. -
Você pode terminar padrões com uma barra (
/) para especificar um diretório. -
Você pode negar um padrão ao fazê-lo iniciar com um ponto de exclamação (
!).
Padrões de nome de arquivo são como expressões regulares simplificadas usadas em ambiente shell.
Um asterisco (*) casa com zero ou mais caracteres; [abc] casa com qualquer caracter dentro dos colchetes (neste caso, a, b ou c); um ponto de interrogação (?) casa com um único caracter qualquer; e caracteres entre colchetes separados por hífen ([0-9]) casam com qualquer caracter entre eles (neste caso, de 0 a 9).
Você também pode usar dois asteriscos para criar uma expressão que case com diretórios aninhados; a/**/z casaria com a/z, a/b/z, a/b/c/z, e assim por diante.
Aqui está outro exemplo de arquivo .gitignore:
# ignorar arquivos com extensão .a
*.a
# mas rastrear o arquivo lib.a, mesmo que você esteja ignorando os arquivos .a acima
!lib.a
# ignorar o arquivo TODO apenas no diretório atual, mas não em subdir/TODO
/TODO
# ignorar todos os arquivos no diretório build/
build/
# ignorar doc/notes.txt, mas não doc/server/arch.txt
doc/*.txt
# ignorar todos os arquivos .pdf no diretório doc/
doc/**/*.pdf|
Tip
|
O GitHub mantém uma lista bem abrangente com bons exemplos de arquivo |
|
Note
|
Em casos simples, um repositório deve ter um único arquivo Está fora do escopo deste livro explicar os detalhes de múltiplos arquivos |
Visualizando Suas Alterações Dentro e Fora do Stage
Se o comando git status for vago demais para você — você quer saber exatamente o que você alterou, não apenas quais arquivos foram alterados — você pode usar o comando git diff.
Nós explicaremos o git diff em detalhes mais tarde, mas provavelmente você vai usá-lo com maior frequência para responder a essas duas perguntas: O que você alterou mas ainda não mandou para o stage (estado preparado)?
E o que está no stage, pronto para o commit?
Apesar de o git status responder a essas perguntas de forma genérica, listando os nomes dos arquivos, o git diff exibe exatamente as linhas que foram adicionadas e removidas — o patch, como costumava se chamar.
Digamos que você altere o arquivo README e o mande para o stage e então altere o arquivo CONTRIBUTING.md sem mandá-lo para o stage.
Se você executar o comando git status, você verá mais uma vez alguma coisa como o seguinte:
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: README
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: CONTRIBUTING.mdPara ver o que você alterou mas ainda não mandou para o stage, digite o comando git diff sem nenhum argumento:
$ git diff
diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
index 8ebb991..643e24f 100644
--- a/CONTRIBUTING.md
+++ b/CONTRIBUTING.md
@@ -65,7 +65,8 @@ branch directly, things can get messy.
Please include a nice description of your changes when you submit your PR;
if we have to read the whole diff to figure out why you're contributing
in the first place, you're less likely to get feedback and have your change
-merged in.
+merged in. Also, split your changes into comprehensive chunks if your patch is
+longer than a dozen lines.
If you are starting to work on a particular area, feel free to submit a PR
that highlights your work in progress (and note in the PR title that it'sEsse comando compara o que está no seu diretório de trabalho com o que está no stage. O resultado permite que você saiba quais alterações você fez que ainda não foram mandadas para o stage.
Se você quiser ver as alterações que você mandou para o stage e que entrarão no seu próximo commit, você pode usar git diff --staged.
Este comando compara as alterações que estão no seu stage com o seu último commit:
$ git diff --staged
diff --git a/README b/README
new file mode 100644
index 0000000..03902a1
--- /dev/null
+++ b/README
@@ -0,0 +1 @@
+My ProjectÉ importante notar que o git diff sozinho não mostra todas as alterações feitas desde o seu último commit — apenas as alterações que ainda não estão no stage (não-preparado).
Isso pode ser confuso porque, se você já tiver mandado todas as suas alterações para o stage, a saída do git diff vai ser vazia.
Um outro exemplo: se você mandar o arquivo CONTRIBUTING.md para o stage e então alterá-lo, você pode usar o git diff para ver as alterações no arquivo que estão no stage e também as que não estão.
Se o nosso ambiente se parecer com isso:
$ git add CONTRIBUTING.md
$ echo '# test line' >> CONTRIBUTING.md
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: CONTRIBUTING.md
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: CONTRIBUTING.mdAgora você poderá usar o git diff para ver o que ainda não foi mandado para o stage:
$ git diff
diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
index 643e24f..87f08c8 100644
--- a/CONTRIBUTING.md
+++ b/CONTRIBUTING.md
@@ -119,3 +119,4 @@ at the
## Starter Projects
See our [projects list](https://github.com/libgit2/libgit2/blob/development/PROJECTS.md).
+# test linee git diff --cached para ver o que você já mandou para o stage até agora (--staged e --cached são sinônimos):
$ git diff --cached
diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
index 8ebb991..643e24f 100644
--- a/CONTRIBUTING.md
+++ b/CONTRIBUTING.md
@@ -65,7 +65,8 @@ branch directly, things can get messy.
Please include a nice description of your changes when you submit your PR;
if we have to read the whole diff to figure out why you're contributing
in the first place, you're less likely to get feedback and have your change
-merged in.
+merged in. Also, split your changes into comprehensive chunks if your patch is
+longer than a dozen lines.
If you are starting to work on a particular area, feel free to submit a PR
that highlights your work in progress (and note in the PR title that it's|
Note
|
Git Diff em uma Ferramenta Externa
Nós continuaremos usando o comando |
Fazendo Commit das Suas Alterações
Agora que sua área de stage está preparada do jeito que você quer, você pode fazer commit das suas alterações.
Lembre-se que qualquer coisa que ainda não foi enviada para o stage — qualquer arquivo que você tenha criado ou alterado e que ainda não tenha sido adicionado com git add — não entrará nesse commit.
Esses arquivos permanecerão no seu disco como arquivos alterados.
Nesse caso, digamos que, da última vez que você executou git status, você viu que tudo estava no stage, então você está pronto para fazer commit de suas alterações.
O jeito mais simples de fazer commit é digitar git commit:
$ git commitFazendo isso, será aberto o editor de sua escolha.
|
Note
|
O editor é determinado pela variável de ambiente |
O editor mostra o seguinte texto (este é um exemplo da tela do Vim):
# Please enter the commit message for your changes. Lines starting
# with '#' will be ignored, and an empty message aborts the commit.
# On branch master
# Your branch is up-to-date with 'origin/master'.
#
# Changes to be committed:
# new file: README
# modified: CONTRIBUTING.md
#
~
~
~
".git/COMMIT_EDITMSG" 9L, 283CVocê pode ver que a mensagem de commit padrão contém a saída mais recente do comando git status, comentada, e uma linha em branco no topo.
Você pode remover esses comentários e digitar sua mensagem de commit, ou você pode deixá-los lá para ajudá-lo a lembrar o que faz parte do commit.
|
Note
|
Para um lembrete ainda mais explícito do que você alterou, você pode passar a opção |
Quando você sair do editor, o Git criará seu commit com essa mensagem (com os comentários e diferenças removidos).
Alternativamente, você pode digitar sua mensagem de commit diretamente na linha de comando, depois da opção -m do comando commit, assim:
$ git commit -m "Story 182: Fix benchmarks for speed"
[master 463dc4f] Story 182: Fix benchmarks for speed
2 files changed, 2 insertions(+)
create mode 100644 READMEVocê acaba de criar seu primeiro commit!
Veja que a saída do comando fornece algumas informações: em qual branch foi feito o commit (master), seu checksum SHA-1 (463dc4f), quantos arquivos foram alterados e estatísticas sobre o número de linhas adicionadas e removidas.
Lembre-se de que o commit grava o snapshot que você deixou na área de stage. Qualquer alteração que você não tiver mandado para o stage permanecerá como estava, em seu lugar; você pode executar outro commit para adicioná-la ao seu histórico. Toda vez que você executa um commit, você está gravando um snapshot do seu projeto que você pode usar posteriormente para fazer comparações, ou mesmo restaurá-lo.
Pulando a Área de Stage
Mesmo sendo incrivelmente útil para preparar commits exatamente como você quer, a área de stage algumas vezes é um pouco mais complexa do que o necessário.
Se você quiser pular a área de stage, o Git fornece um atalho simples.
A opção -a, do comando git commit, faz o Git mandar todos arquivos rastreados para o stage automaticamente, antes de fazer o commit, permitindo que você pule a parte do git add:
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: CONTRIBUTING.md
no changes added to commit (use "git add" and/or "git commit -a")
$ git commit -a -m 'added new benchmarks'
[master 83e38c7] added new benchmarks
1 file changed, 5 insertions(+), 0 deletions(-)Perceba que, nesse caso, você não tem que executar git add antes, para adicionar o arquivo CONTRIBUTING.md ao commit.
Isso ocorre porque a opção -a inclui todos os arquivos alterados.
Isso é conveniente, mas cuidado; algumas vezes esta opção fará você incluir alterações indesejadas.
Removendo Arquivos
Para remover um arquivo do Git, você tem que removê-lo dos seus arquivos rastreados (mais precisamente, removê-lo da sua área de stage) e então fazer um commit.
O comando git rm faz isso, e também remove o arquivo do seu diretório de trabalho para que você não o veja como um arquivo não-rastreado nas suas próximas interações.
Se você simplesmente remover o arquivo do seu diretório, ele aparecerá sob a área “Changes not staged for commit” (isto é, fora do stage) da saída do seu git status:
$ rm PROJECTS.md
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes not staged for commit:
(use "git add/rm <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
deleted: PROJECTS.md
no changes added to commit (use "git add" and/or "git commit -a")Mas, se você executar git rm, o arquivo será preparado para remoção (retirado do stage):
$ git rm PROJECTS.md
rm 'PROJECTS.md'
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
deleted: PROJECTS.mdDa próxima vez que você fizer um commit, o arquivo será eliminado e não será mais rastreado.
Se o arquivo tiver sido alterado ou se já tiver adicionado à área de stage, você terá que forçar a remoção com a opção -f.
Essa é uma medida de segurança para prevenir a exclusão acidental de dados que ainda não tenham sido gravados em um snapshot e que não poderão ser recuperados do histórico.
Outra coisa útil que você pode querer fazer é manter o arquivo no seu diretório de trabalho, mas removê-lo da sua área de stage.
Em outras palavras, você pode querer manter o arquivo no seu disco rígido, mas não deixá-lo mais sob controle do Git.
Isso é particularmente útil se você esquecer de adicionar alguma coisa ao seu arquivo .gitignore e, acidentalmente, mandá-la para o stage, como um grande arquivo de log ou um monte de arquivos compilados .a.
Para fazer isso, use a opção --cached:
$ git rm --cached READMEVocê pode passar arquivos, diretórios e padrões de nomes para o comando git rm.
Isso quer dizer que você pode fazer coisas como:
$ git rm log/\*.logNote a barra invertida (\) na frente do *.
Isso é necessário porque o Git faz sua própria expansão de nomes de arquivos em adição a que é feita pela sua shell.
Esse comando remove todos os arquivos que tenham a extensão .log do diretório log/.
Ou, você pode fazer algo como o seguinte:
$ git rm \*~Esse comando remove todos os arquivos cujos nomes terminem com um ~.
Movendo Arquivos
Diferentemente de outros sistemas de controle de versão, o Git não rastreia explicitamente a movimentação de arquivos. Se você renomear um arquivo no Git, ele não armazena metadados indicando que determinado arquivo foi renomeado. Porém, o Git é bastante esperto para perceber isso depois do fato ocorrido — nós trataremos de movimentação de arquivos daqui a pouco.
Assim, é um pouco confuso o fato de o Git ter um comando mv.
Se você quiser renomear um arquivo no Git, você pode executar alguma coisa como:
$ git mv arq_origem arq_destinoe vai funcionar bem. Na verdade, se você executar alguma coisa assim e verificar o status, você vai ver que o Git considera que arquivo foi renomeado:
$ git mv README.md README
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
renamed: README.md -> READMEContudo, isso é equivalente a executar algo como:
$ mv README.md README
$ git rm README.md
$ git add READMEO Git percebe que, implicitamente, se trata de um arquivo renomeado, de maneira que não importa se você renomear um arquivo desse jeito ou com o comando mv.
A única diferença real é que git mv é um comando em vez de três — é uma função de conveniência.
Mais importante, você pode usar qualquer ferramenta que quiser para renomear um arquivo e cuidar do add/rm depois, antes de fazer o commit.